Ins and outs of opendataes: a guide for collaboration
Jorge Cimentada and Jorge Lopez
2021-04-13
Source:vignettes/ins-and-outs-of-opendataes-guide-for-collaboration.Rmd
ins-and-outs-of-opendataes-guide-for-collaboration.Rmdopendataes is package that was ultimately though of to be maintained by the R community. The package is extremely useful in automating some tasks but also limited in some aspects. This vignette is aimed at describing in detail how the package works so that new users can understand the inner workings of opendataes and contribute more easily.
How does this work anyway?
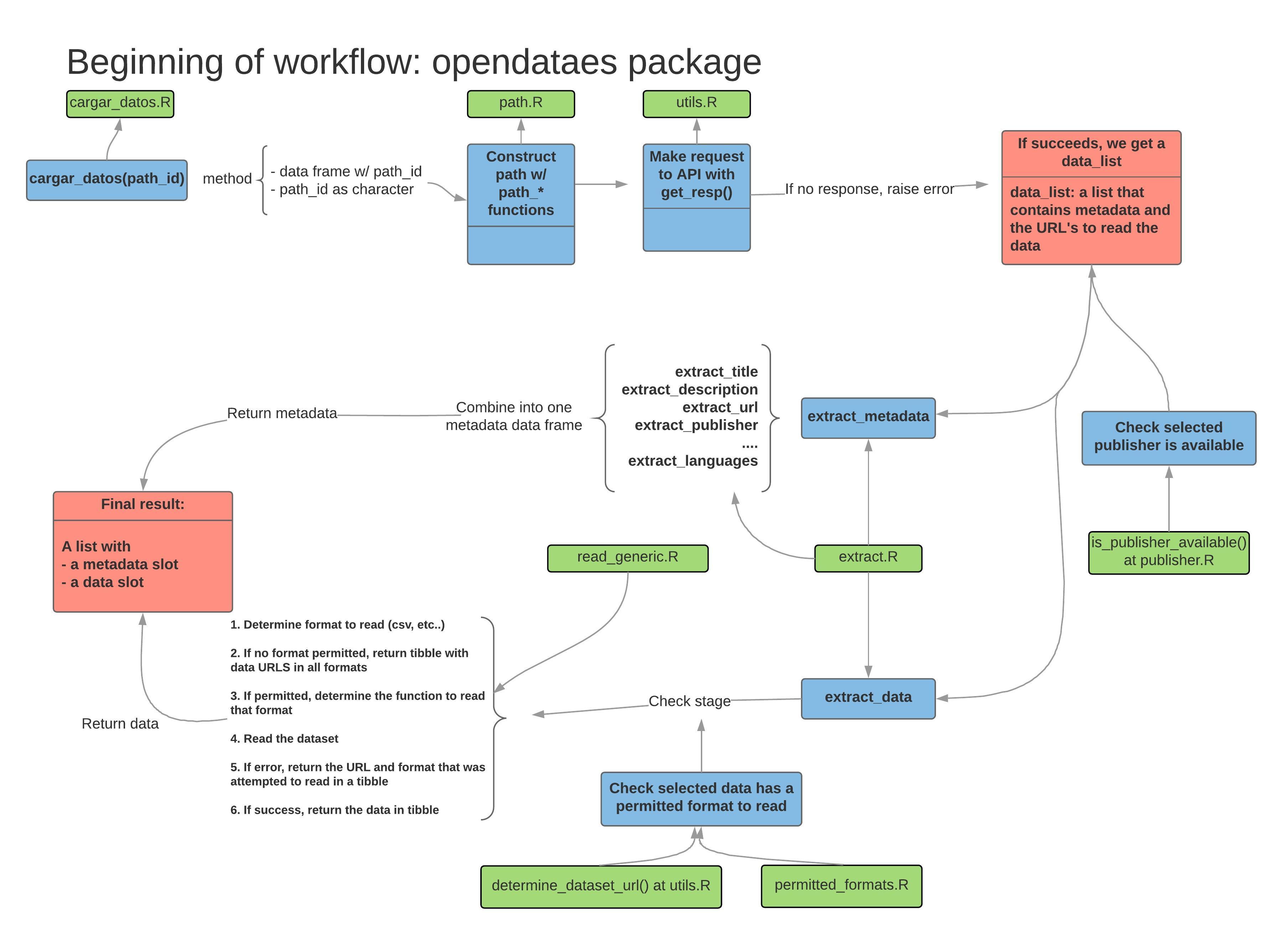
Woah, that’s a lot of information. The package has three steps:
- Preparing the path and requesting data from the API
- Extracting the metadata
- Extracting the data
In the image above, the first step is the horizontal diagram at the top while the last two steps are the horizontal diagrams at the bottom. We’ll go step by step and tear it apart. First, let’s look at the legend of each box
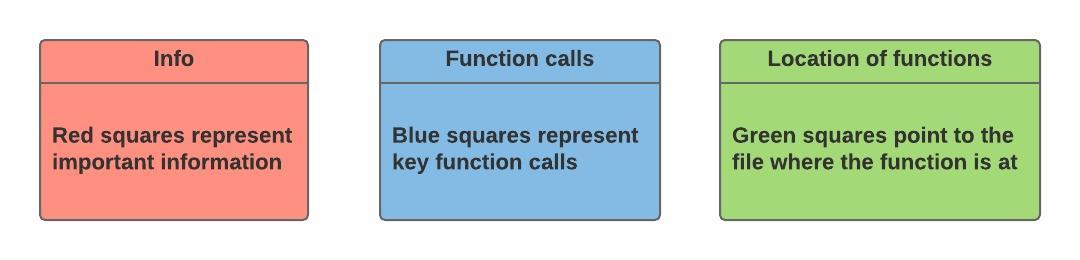
I’ll explain it further just to make it clearer. The red boxes are information boxes. That is, they don’t document a function call in the process, so just take it as an explanation of the process. The blue boxes are the most important because they document the function calls. That is, each of the blue boxes represent a function being called that represents an important step in the process of reading the data. Finally, the green boxes represent where the function in the blue box is at in the package structure. This is handy when you want to read through the source code of the function without much hassle.
That said, let’s explore the first step in the process.
Preparing and calling the API

The first step begins with openes_load, which is the main function. It accepts the typical path_id of the dataset as a string (read the README or other vignette for some simpler cases). For example:
#>
#> Please cite as:
#> Cimentada, J. and Jorge Lopez (2019). Interact with the datos.gob.es API to download public data from all of Spain R package version 0.0.1
library(opendataes)
path_id <- 'l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona'
openes_load(path_id)However, it also has a method for a dataframe, as the graph suggests. This method is strictly aimed at dataframes returned by openes_keywords so it checks the format of the dataframe before hand.
openes_load
#> function (x, encoding = "UTF-8", guess_encoding = TRUE, ...)
#> {
#> x <- if (is.data.frame(x))
#> check_keywords_df(x)
#> else x
#> UseMethod("openes_load", x)
#> }openes_load redirects to check_keywords_df, an internal function that checks whether the dataframe has the path_id column, among other checks. Finally, once the check succeeds, it assigns the dataframe a class datos_gob_es_keywords and passes it to the method dispatch UseMethod. The method for the class datos_gob_es_keywords merely subsets the path_id column to get the string and read it using the character method of openes_load:
opendataes:::openes_load.datos_gob_es_keywords
#> function (x, encoding = "UTF-8", guess_encoding = TRUE, ...)
#> {
#> openes_load(x$path_id, encoding, guess_encoding, ...)
#> }So we end up with the same call as if we would’ve called the main argument with a string containing the path_id. As the diagram suggests, you can find these functions in the R script R/openes_load.R in the Github repository. Once openes_load passes the string as the main argument it constructs the whole path for the API using a family of functions found in R/path.R. More concretely, it defines the complete path using path_dataset_id(path_id) which returns the direct path of the API to query the data set.
At the end of this preprocessing step, openes_load passes this complete path to get_resp which sends a GET request to the API.
We can see the whole process in the character method of openes_load:
opendataes:::openes_load.character
#> function (x, encoding = "UTF-8", guess_encoding = TRUE, ...)
#> {
#> if (!is.character(x) || length(x) > 1)
#> stop("`x` must be a character of length 1")
#> if (!is.character(encoding) || length(encoding) > 1)
#> stop("`encoding` must be a character of length 1")
#> if (!is.logical(guess_encoding) || length(guess_encoding) >
#> 1)
#> stop("`guess_encoding` must be a logical of length 1")
#> raw_json <- get_resp(path_dataset_id(x))
#> if (!data_list_correct(raw_json))
#> return(list())
#> data_list <- raw_json$result$items[[1]]
#> if (!is_publisher_available(data_list)) {
#> stop("Publisher not available. Please check publishers_available() to get the available ones.")
#> }
#> returned_list <- structure(list(metadata = extract_metadata(data_list),
#> data = suppress_all(extract_data(data_list, encoding,
#> guess_encoding, ...))), class = "datos_gob_es")
#> returned_list
#> }The function get_resp returns a list with the response from the API, which we’ve interally called a data_list. You will encounter this name in several places in the package as argument names or in the internal documentation. The data_list is just a list that contains the metadata of the dataset and the links to the data from the original publisher (for example, the direct links to the data from the Ayuntamiento de Madrid or Málaga) along with some information from the GET request.
To visualize a real example of a data_list we can call it directly using the previous path_id:
# Note that these specific function calls might change in the future,
# but for the sake of showing the format of a data_list we run it.
data_list <- opendataes:::get_resp(opendataes:::path_dataset_id(path_id))
data_list
#> $format
#> [1] "linked-data-api"
#>
#> $version
#> [1] "0.2"
#>
#> $result
#> $result$`_about`
#> [1] "http://datos.gob.es/apidata/catalog/dataset/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona.json"
#>
#> $result$definition
#> [1] "http://datos.gob.es/apidata/catalog/meta/dataset/_id.json"
#>
#> $result$extendedMetadataVersion
#> [1] "http://datos.gob.es/apidata/catalog/dataset/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona.json?_metadata=all"
#>
#> $result$first
#> [1] "http://datos.gob.es/apidata/catalog/dataset/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona.json?_page=0"
#>
#> $result$hasPart
#> [1] "http://datos.gob.es/apidata/catalog/dataset/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona.json"
#>
#> $result$isPartOf
#> [1] "http://datos.gob.es/apidata/catalog/dataset/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona.json"
#>
#> $result$items
#> $result$items[[1]]
#> $result$items[[1]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona"
#>
#> $result$items[[1]]$description
#> $result$items[[1]]$description[[1]]
#> $result$items[[1]]$description[[1]]$`_value`
#> [1] "Absolute results of the European Parliament elections of the city of Barcelona"
#>
#> $result$items[[1]]$description[[1]]$`_lang`
#> [1] "en"
#>
#>
#> $result$items[[1]]$description[[2]]
#> $result$items[[1]]$description[[2]]$`_value`
#> [1] "Resultados absolutos de las elecciones al Parlamento Europeo de la ciudad de Barcelona"
#>
#> $result$items[[1]]$description[[2]]$`_lang`
#> [1] "es"
#>
#>
#> $result$items[[1]]$description[[3]]
#> $result$items[[1]]$description[[3]]$`_value`
#> [1] "Resultats absoluts de les eleccions al Parlament Europeu de la ciutat de Barcelona"
#>
#> $result$items[[1]]$description[[3]]$`_lang`
#> [1] "ca"
#>
#>
#>
#> $result$items[[1]]$distribution
#> $result$items[[1]]$distribution[[1]]
#> $result$items[[1]]$distribution[[1]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona/resource/683eae1e-5205-4cdb-a1c7-01d629034f7d"
#>
#> $result$items[[1]]$distribution[[1]]$accessURL
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/5745630c-77c0-431b-873d-4e83e021ebea/resource/d2350e16-4e9a-47f9-b7ae-6d72ef955371/download"
#>
#> $result$items[[1]]$distribution[[1]]$format
#> $result$items[[1]]$distribution[[1]]$format[[1]]
#> $result$items[[1]]$distribution[[1]]$format[[1]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona/resource/683eae1e-5205-4cdb-a1c7-01d629034f7d/format"
#>
#> $result$items[[1]]$distribution[[1]]$format[[1]]$type
#> [1] "http://purl.org/dc/terms/IMT"
#>
#> $result$items[[1]]$distribution[[1]]$format[[1]]$value
#> [1] "text/csv"
#>
#>
#> $result$items[[1]]$distribution[[1]]$format[[2]]
#> [1] "http://publications.europa.eu/resource/authority/file-type/CSV"
#>
#>
#> $result$items[[1]]$distribution[[1]]$identifier
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/est-eleccions-europees-seccio-censal/resource/d2350e16-4e9a-47f9-b7ae-6d72ef955371"
#>
#> $result$items[[1]]$distribution[[1]]$title
#> $result$items[[1]]$distribution[[1]]$title[[1]]
#> $result$items[[1]]$distribution[[1]]$title[[1]]$`_value`
#> [1] "2009_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[1]]$title[[1]]$`_lang`
#> [1] "es"
#>
#>
#> $result$items[[1]]$distribution[[1]]$title[[2]]
#> $result$items[[1]]$distribution[[1]]$title[[2]]$`_value`
#> [1] "2009_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[1]]$title[[2]]$`_lang`
#> [1] "en"
#>
#>
#> $result$items[[1]]$distribution[[1]]$title[[3]]
#> $result$items[[1]]$distribution[[1]]$title[[3]]$`_value`
#> [1] "2009_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[1]]$title[[3]]$`_lang`
#> [1] "ca"
#>
#>
#>
#> $result$items[[1]]$distribution[[1]]$type
#> [1] "http://www.w3.org/ns/dcat#Distribution"
#>
#>
#> $result$items[[1]]$distribution[[2]]
#> $result$items[[1]]$distribution[[2]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona/resource/7c0938e8-245d-4c5e-bb69-31bd881fd84a"
#>
#> $result$items[[1]]$distribution[[2]]$accessURL
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/5745630c-77c0-431b-873d-4e83e021ebea/resource/8aa88b93-727b-45be-a11f-5dcea459a47b/download"
#>
#> $result$items[[1]]$distribution[[2]]$format
#> $result$items[[1]]$distribution[[2]]$format[[1]]
#> $result$items[[1]]$distribution[[2]]$format[[1]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona/resource/7c0938e8-245d-4c5e-bb69-31bd881fd84a/format"
#>
#> $result$items[[1]]$distribution[[2]]$format[[1]]$type
#> [1] "http://purl.org/dc/terms/IMT"
#>
#> $result$items[[1]]$distribution[[2]]$format[[1]]$value
#> [1] "text/csv"
#>
#>
#> $result$items[[1]]$distribution[[2]]$format[[2]]
#> [1] "http://publications.europa.eu/resource/authority/file-type/CSV"
#>
#>
#> $result$items[[1]]$distribution[[2]]$identifier
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/est-eleccions-europees-seccio-censal/resource/8aa88b93-727b-45be-a11f-5dcea459a47b"
#>
#> $result$items[[1]]$distribution[[2]]$title
#> $result$items[[1]]$distribution[[2]]$title[[1]]
#> $result$items[[1]]$distribution[[2]]$title[[1]]$`_value`
#> [1] "2014_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[2]]$title[[1]]$`_lang`
#> [1] "es"
#>
#>
#> $result$items[[1]]$distribution[[2]]$title[[2]]
#> $result$items[[1]]$distribution[[2]]$title[[2]]$`_value`
#> [1] "2014_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[2]]$title[[2]]$`_lang`
#> [1] "ca"
#>
#>
#> $result$items[[1]]$distribution[[2]]$title[[3]]
#> $result$items[[1]]$distribution[[2]]$title[[3]]$`_value`
#> [1] "2014_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[2]]$title[[3]]$`_lang`
#> [1] "en"
#>
#>
#>
#> $result$items[[1]]$distribution[[2]]$type
#> [1] "http://www.w3.org/ns/dcat#Distribution"
#>
#>
#> $result$items[[1]]$distribution[[3]]
#> $result$items[[1]]$distribution[[3]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona/resource/c4000225-3557-4b8d-af2f-dba6546b37d8"
#>
#> $result$items[[1]]$distribution[[3]]$accessURL
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/5745630c-77c0-431b-873d-4e83e021ebea/resource/bd503ce0-2848-4918-b2fd-71325f0d7dcc/download"
#>
#> $result$items[[1]]$distribution[[3]]$format
#> $result$items[[1]]$distribution[[3]]$format[[1]]
#> $result$items[[1]]$distribution[[3]]$format[[1]]$`_about`
#> [1] "http://datos.gob.es/catalogo/l01080193-resultados-absolutos-de-las-elecciones-al-parlamento-europeo-de-la-ciudad-de-barcelona/resource/c4000225-3557-4b8d-af2f-dba6546b37d8/format"
#>
#> $result$items[[1]]$distribution[[3]]$format[[1]]$type
#> [1] "http://purl.org/dc/terms/IMT"
#>
#> $result$items[[1]]$distribution[[3]]$format[[1]]$value
#> [1] "text/csv"
#>
#>
#> $result$items[[1]]$distribution[[3]]$format[[2]]
#> [1] "http://publications.europa.eu/resource/authority/file-type/CSV"
#>
#>
#> $result$items[[1]]$distribution[[3]]$identifier
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/est-eleccions-europees-seccio-censal/resource/bd503ce0-2848-4918-b2fd-71325f0d7dcc"
#>
#> $result$items[[1]]$distribution[[3]]$title
#> $result$items[[1]]$distribution[[3]]$title[[1]]
#> $result$items[[1]]$distribution[[3]]$title[[1]]$`_value`
#> [1] "2019_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[3]]$title[[1]]$`_lang`
#> [1] "en"
#>
#>
#> $result$items[[1]]$distribution[[3]]$title[[2]]
#> $result$items[[1]]$distribution[[3]]$title[[2]]$`_value`
#> [1] "2019_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[3]]$title[[2]]$`_lang`
#> [1] "ca"
#>
#>
#> $result$items[[1]]$distribution[[3]]$title[[3]]
#> $result$items[[1]]$distribution[[3]]$title[[3]]$`_value`
#> [1] "2019_Eleccions_Parlament_Europeu.csv"
#>
#> $result$items[[1]]$distribution[[3]]$title[[3]]$`_lang`
#> [1] "es"
#>
#>
#>
#> $result$items[[1]]$distribution[[3]]$type
#> [1] "http://www.w3.org/ns/dcat#Distribution"
#>
#>
#>
#> $result$items[[1]]$identifier
#> [1] "https://opendata-ajuntament.barcelona.cat/data/dataset/est-eleccions-europees-seccio-censal"
#>
#> $result$items[[1]]$issued
#> [1] "mié, 13 mar 2013 23:00:00 GMT+0000"
#>
#> $result$items[[1]]$keyword
#> $result$items[[1]]$keyword[[1]]
#> [1] "Absolutos"
#>
#> $result$items[[1]]$keyword[[2]]
#> [1] "Año 2009"
#>
#> $result$items[[1]]$keyword[[3]]
#> [1] "Año 2014"
#>
#> $result$items[[1]]$keyword[[4]]
#> [1] "Año 2019"
#>
#> $result$items[[1]]$keyword[[5]]
#> [1] "Barrio"
#>
#> $result$items[[1]]$keyword[[6]]
#> [1] "Barrios Barcelona"
#>
#> $result$items[[1]]$keyword[[7]]
#> [1] "Elecciones europeas"
#>
#> $result$items[[1]]$keyword[[8]]
#> [1] "Secciones censales"
#>
#>
#> $result$items[[1]]$publisher
#> [1] "http://datos.gob.es/recurso/sector-publico/org/Organismo/L01080193"
#>
#> $result$items[[1]]$references
#> $result$items[[1]]$references[[1]]
#> [1] "https://www.bcn.cat/estadistica/angles/dades/telec/eur/index.htm"
#>
#> $result$items[[1]]$references[[2]]
#> [1] "https://www.bcn.cat/estadistica/castella/dades/telec/eur/index.htm"
#>
#> $result$items[[1]]$references[[3]]
#> [1] "https://www.bcn.cat/estadistica/catala/dades/telec/eur/index.htm"
#>
#>
#> $result$items[[1]]$theme
#> [1] "http://datos.gob.es/kos/sector-publico/sector/sector-publico"
#>
#> $result$items[[1]]$title
#> $result$items[[1]]$title[[1]]
#> $result$items[[1]]$title[[1]]$`_value`
#> [1] "Absolute results of the European Parliament elections of the city of Barcelona"
#>
#> $result$items[[1]]$title[[1]]$`_lang`
#> [1] "en"
#>
#>
#> $result$items[[1]]$title[[2]]
#> $result$items[[1]]$title[[2]]$`_value`
#> [1] "Resultados absolutos de las elecciones al Parlamento Europeo de la ciudad de Barcelona"
#>
#> $result$items[[1]]$title[[2]]$`_lang`
#> [1] "es"
#>
#>
#> $result$items[[1]]$title[[3]]
#> $result$items[[1]]$title[[3]]$`_value`
#> [1] "Resultats absoluts de les eleccions al Parlament Europeu de la ciutat de Barcelona"
#>
#> $result$items[[1]]$title[[3]]$`_lang`
#> [1] "ca"
#>
#>
#>
#> $result$items[[1]]$type
#> [1] "http://www.w3.org/ns/dcat#Dataset"
#>
#>
#>
#> $result$itemsPerPage
#> [1] 10
#>
#> $result$page
#> [1] 0
#>
#> $result$startIndex
#> [1] 1
#>
#> $result$type
#> $result$type[[1]]
#> [1] "http://purl.org/linked-data/api/vocab#ListEndpoint"
#>
#> $result$type[[2]]
#> [1] "http://purl.org/linked-data/api/vocab#Page"Before we extract the metadata and data, openes_load checks that the data_list is in the expected format, because otherwise none of the functions in the package would work. If the data_list is not in the correct format, openes_load returns an empty list.
Note: opendataes really pushes for consistent outputs. That is, it usually returns a list with two slots containing the metadata and data and if the data poses some sort of problem, openes_load should return the same list with two slots but without the data itself. However, if the data_list is not in the correct format it means that the API is returning something odd in the first place. This is regardless of the quality, standardization or format of the dataset. In this scenario openes_load returns an empty list but this is open to debate. This is an area for improvements for new comers.
Getting back to the data_list, it is messy and not very intuitive. This is when we move to the second step of the diagram.
Extracting the metadata
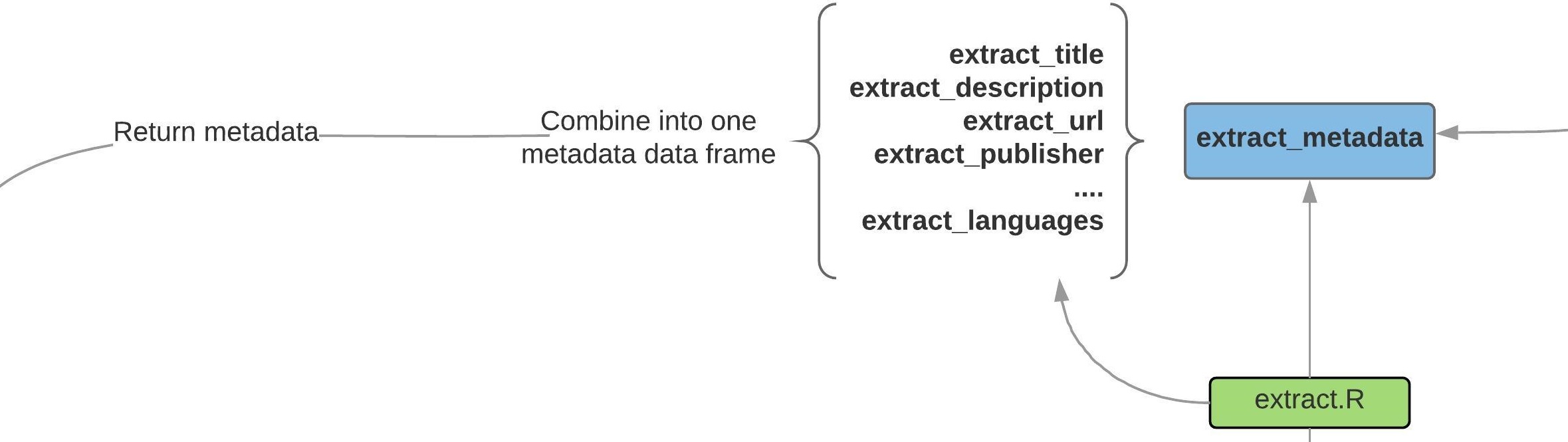
The metadata is scattered around the data_list but it keeps consistent names so opendataes provides several extract_* functions that are present in the diagram. We combine all of these ‘helper’ functions into extract_metadata to provide a general tibble of metadata. In the example below, we need to dig deeper into the list structure of data_list to get to where the data actually is.
For example..
# This is the slot where the data is. This is the case
# even when there are several datasets to read.
# It is safe only to search HERE for the data
# and metadata
data_list <- data_list$result$items[[1]]
opendataes:::extract_metadata(data_list)
#> # A tibble: 3 x 8
#> keywords language description url date_issued date_modified
#> <chr> <chr> <chr> <chr> <dttm> <chr>
#> 1 Absolutos;… en Absolute resu… http://… 2013-03-13 23:00:00 No modificat…
#> 2 Absolutos;… es Resultados ab… http://… 2013-03-13 23:00:00 No modificat…
#> 3 Absolutos;… ca Resultats abs… http://… 2013-03-13 23:00:00 No modificat…
#> # … with 2 more variables: publisher <chr>, publisher_data_url <chr>Inside this function we’re just calling separate extract_* functions to grab each piece of metadata. For example..
keywords <- extract_keywords(data_list)
description <- extract_description(data_list)
languages <- extract_language(data_list)
url_path <- extract_url(data_list)Once that’s done, the metadata is ready. For more detailed readings of the source code, each of these functions are located in the R/extract.R path. Now we move on to the trickiest step: extracting the data.
Extracting the data
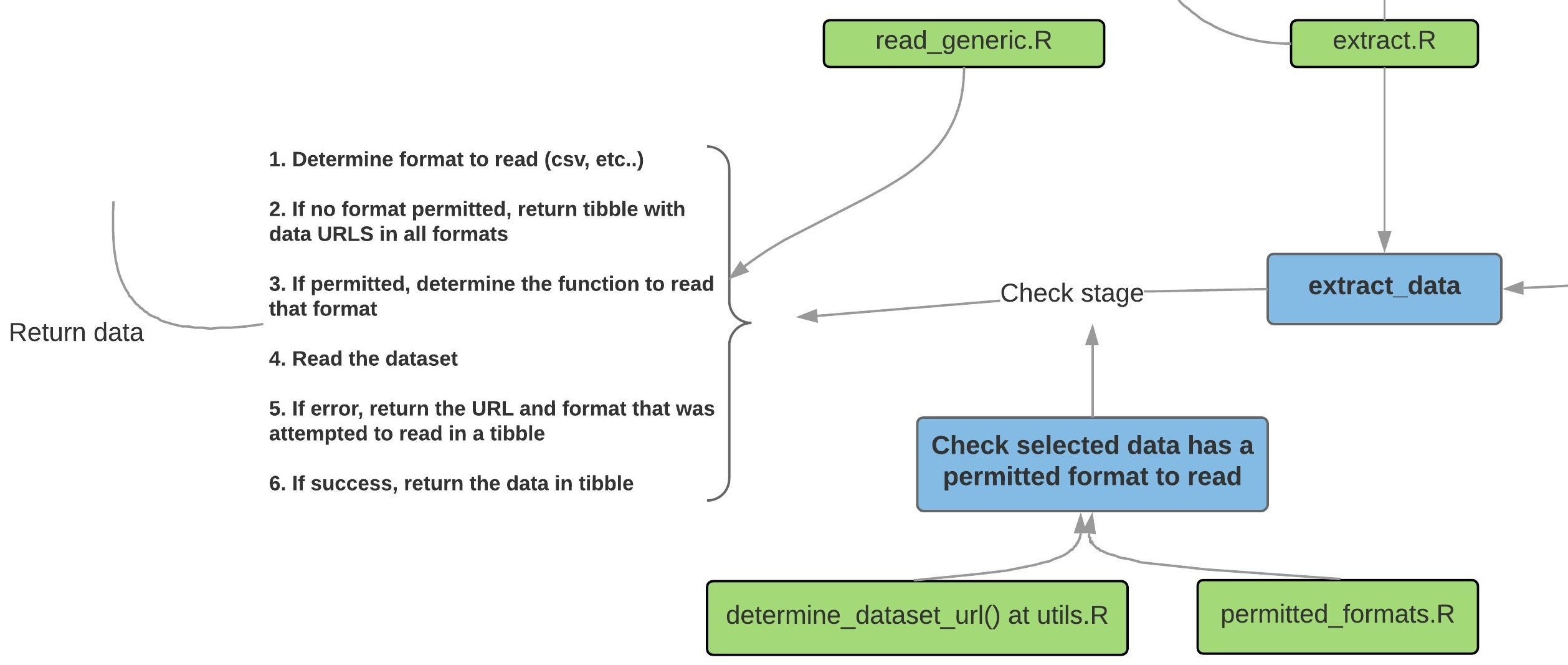
The first step is passing the data_list from above to extract_data which can be located at the path R/extract.R. The difficult part of reading the data is due to the fact that different publishers keep datasets with different formats. For example, the Ayuntamiento de Madrid might have a csv file with only one excel sheet in an organized tabular format but the Ayuntamiento de Arganda del Rey might have several sheets with several tables inside each sheet. There’s really nothing that can be done about that if the aim of the package is to scale the data reading process across several publishers. The chosen solution, we believe, is the most conservative: limit the publishers and formats that opendataes can read and increase these two as their standardization practices grow.
The first step that openes_load takes before calling extract_data functions is to check whether the data comes from our permitted publishers. If the dataset is not from an available publisher, it raises an error. This is done via opendataes:::is_publisher_available which extracts the publisher from the data_list and matches it with our list of available publishers.
The criteria we think best to include new publishers is to check by brute force whether they have patterns of standardization. For example, the first publisher we accepted as reliable was ‘Ayuntamiento of Barcelona’ because we repeatedly found ourselves reading datasets from the same format which were very consistent and easy to read. For the list of available publishers that opendataes can read, we can look at opendataes::publishers_available.
publishers_available
#> # A tibble: 11 x 2
#> publishers publisher_code
#> <chr> <chr>
#> 1 Ayuntamiento de Barcelona L01080193
#> 2 Ayuntamiento de Madrid L01280796
#> 3 Ayuntamiento de Valencia L01462508
#> 4 Ayuntamiento de Las Palmas de Gran Canaria L01350167
#> 5 Ayuntamiento de Bilbao L01480209
#> 6 Ayuntamiento de Zaragoza L01502973
#> 7 Ayuntamiento de Malaga L01290672
#> 8 Ayuntamiento de Gijon L01330241
#> 9 Ayuntamiento de Santander L01390759
#> 10 Ayuntamiento de Alcobendas L01280066
#> 11 Junta de Castilla y Leon A07002862This is one of the main areas were opendataes needs support. We are always welcoming pull requests that would allow us to read new publishers as long as we can have some sort of proof of consistency in their datasets.
The second problem, and very related to the previous, is the formats that opendataes can read. Because standardization across datasets is one of our main concerns, we are interested in reading formats which are consistent and predictable for reading purposes. Fortunately, around 70% of all datasets in datos.gob.es are csv files, a very standard format. For that reason, it is the first format that we give preference for reading. You can check the permitted formats with opendataes::permitted_formats.
permitted_formats
#> [1] "csv"This is one are where we are actively looking for new pull requests as we are interested in broadening the scope of formats that opendataes can read.
From the package’s perspective there are two things that can be done to further increase the number of publishers and formats: push each of our publishers for greater standardization and check whether we can read a reasonable number of file formats from a given publisher.
Having said that, the first thing that extract_data does is to check whether the selected dataset has any of the formats that opendataes can read. If it doesn’t, then it doesn’t attempt to read anything but merely returns the dataset’s URL’s in all the formats available. For example it returns a tibble like this one..
# $`unavailable_formats`
# A tibble: 13 x 3
# name format URL
# <chr> <chr> <chr>
# 1 2018_3T_CARRIL_BICI_CONST~ zip http://opendata-ajuntament.barcelona.cat/resources/bcn/2018_3T_CARRIL_BICI_CO~
# 2 CARRIL_BICI_CONSTRUCCIO.s~ NA http://opendata-ajuntament.barcelona.cat/resources/bcn/CARRIL_BICI_CONSTRUCCI~
# 3 CARRIL_BICI_CONSTRUCCIO.p~ asc http://opendata-ajuntament.barcelona.cat/resources/bcn/CARRIL_BICI_CONSTRUCCI~
# 4 2018_2T_CARRIL_BICI_CONST~ zip http://opendata-ajuntament.barcelona.cat/resources/bcn/2018_2T_CARRIL_BICI_CO~
# 5 CARRIL_BICI_CONSTRUCCIO.g~ json http://opendata-ajuntament.barcelona.cat/resources/bcn/CARRIL_BICI_CONSTRUCCI~
# 6 CARRIL_BICI_CONSTRUCCIO.z~ zip http://opendata-ajuntament.barcelona.cat/resources/bcn/CARRIL_BICI_CONSTRUCCI~
# 7 2017_4T_CARRIL_BICI_CONS.~ zip http://opendata-ajuntament.barcelona.cat/data/dataset/edee68e3-5ff1-43d0-b556~
# 8 2018_1T_CARRIL_BICI_CONS.~ zip http://opendata-ajuntament.barcelona.cat/data/dataset/edee68e3-5ff1-43d0-b556~
# 9 2017_3T_CARRIL_BICI_CONS.~ zip http://opendata-ajuntament.barcelona.cat/data/dataset/edee68e3-5ff1-43d0-b556~
# 10 CARRIL_BICI_CONSTRUCCIO.d~ asc http://opendata-ajuntament.barcelona.cat/resources/bcn/CARRIL_BICI_CONSTRUCCI~
# 11 CARRIL_BICI_CONSTRUCCIO.s~ NA http://opendata-ajuntament.barcelona.cat/resources/bcn/CARRIL_BICI_CONSTRUCCI~
# 12 2017_2T_CARRIL_BICI_CONS.~ zip http://opendata-ajuntament.barcelona.cat/data/dataset/edee68e3-5ff1-43d0-b556~
# 13 2017_1T_CARRIL_BICI_CONS.~ zip http://opendata-ajuntament.barcelona.cat/data/dataset/edee68e3-5ff1-43d0-b556~where the user would get each file name with it’s format and direct URL, in case they want to read it manually. In case the dataset has at least one of the permitted formats, then the process is different: extract_data extracts all URL’s of the permitted format. As an ilustrative example, a dataset could have several files as can be seen in the image below:

The above image shows the accidents in the city of Barcelona for years 2010, 2011, etc.. where each of these datasets is in csv, xlsx and xml formats. What extract_data does is pick the permitted format in the order of preference of opendataes::permitted_formats and extract all of the URL’s for that format. In this case, it would extract all of the URL’s for the accidents in csv for the year 2010, 2011, etc..
Once those URL’s are extracted, a loop begins for each of the URL’s where each URL is passed to read_generic, located at R/read_generic.R, to determine the function to read the data based on the format. Once the function is determined, read_generic attempts to read the URL. If for any reason reading the data raises an error, inside the same loop, extract_datos merely records the format and URL and returns a dataframe with the info that it attempted to read. This is done to preserve the structure of the results and to give the user the option to try to read it manually. If the reading process was successful, then it simply returns the data as a tibble.
This is what really happens behind the scenes with commented code:
# If there is any format to read continue, otherwise return
# A dataset with all formats and their respective URL
# is_file_readable here contains the formats that matched between
# the data_list and the permitted_formats
if (length(is_file_readable) != 0) {
# Determine the NAME of the datafiles
names_datasets <- determine_dataset_name(data_list)
# Make sure the URL's and dataset names are in the same order.
if (!all(names_datasets == is_file_readable)) stop("Data cannot be read because it is not in correct order")
# Create empty list to fill it with the data
output_data <- vector("list", length(is_file_readable))
# Loop over the index of each URL
for (index in seq_along(is_file_readable)) {
# Grab the URL
data_url <- names(is_file_readable)[index]
# Determine the read_ function to be used from the format of the URL
read_generic <- determine_read_generic(data_url)
# Because there are different languages in Spain, set the encoding
# to be used when reading the dataset. This is where the encoding argument
# is passed to
custom_locale <- readr::locale("es", encoding = encoding)
# Try reading the data and saving it in that dataset's slot
# in the list
output_data[[index]] <- try(read_generic(file = data_url, locale = custom_locale, ...), silent = TRUE)
# If there was an error reading the dataset, fill the same slot
# with the format and URL that it attempted to read.
if (inherits(output_data[[index]], "try-error")) {
output_data[[index]] <- tibble::tibble(format = is_file_readable[index],
URL = names(is_file_readable[index]))
}
}
# Assign the names of each data slot so that users can identify which
# name belongs to which dataset.
names(output_data) <- names(names_datasets)
}The process explained above is very messy because of the main problem discussed above: not all datasets are standardized. For example, in one of the csv files from above there could’ve been a starting blank line whereas in the second dataset there was no such line. Manually, this is easy to handle by just providing an argument such as skip to skip the first line. However, once we scale it to different datasets which don’t have a standardized structure, it becomes very messy.
Providing specific arguments to each dataset being read would be too difficult considering that the user never knows the order at which each of the datasets are being read. Moreover, in order for the user to know which arguments should be passed to each dataset, the user would have had to read the data manually in the first place which really misses the whole point of streamlining the process of reading the data automatically.
As a partial solution, opendataes provides the ... argument in openes_load to allow the user to pass generic arguments to all datasets. In a similar line, openes_load allows the user to pass the encoding argument which is passed to the read_generic function when it is appropriate. Of course, any argument passed to ... or encoding will be applied to all datasets being read. Once this process is over, extract_data will always return a list with tibble’s where each tibble could be the data itself or a tibble with the link and format that read_generic attempted to read but failed for some reason.
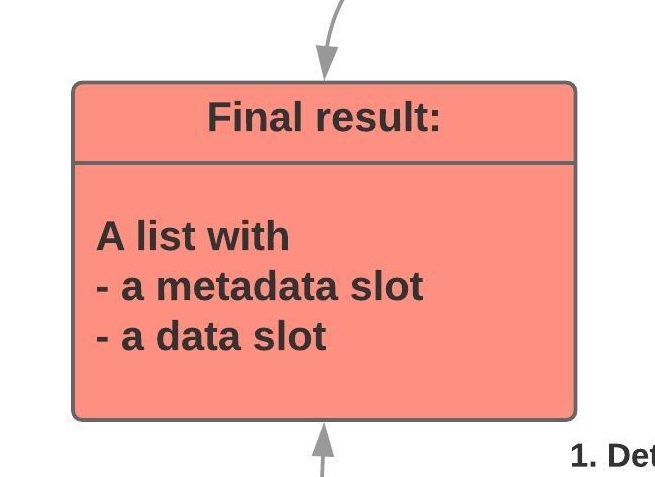
The final step is merely joining both the metadata and data into a list as the below image shows:
This vignette was written as the package became public and the structure might get outdated as time passes by. We aim for the package to grow through new contributors. The package is accepting pull requests and it is open to new features so feel free to file an issue to discuss new ideas at the Github repository here
Site built with pkgdown 1.6.1.
Template by Bootstrapious . Ported to pkgdown by dieghernan.