Visualizando las puntuaciones
Gonzalo Garcia-Castro
Código:vignettes/puntuaciones.Rmd
puntuaciones.RmdEn cada una de estas catas a ciegas de El Comidista
(disponibles en su canal de YouTube)
se presenta una serie de productos de marcas industriales a una o dos
personas expertas en ese tipo de productos. En los vídeos en los que hay
más de una persona puntuando los productos, el equipo de edición asigna
al producto la media de las puntuaciones. La base de datos
puntuaciones muestra las puntuaciones de cada persona del
jurado de forma individual. Ver ?puntuaciones para más
información sobre esta base de datos.
Primero cargamos los paquetes que necesitaremos:
library(comidistar) # contiene los datos y funciones ayudantes
library(dplyr) # para manejar los datos en formato tidy
library(ggplot2) # para visualizar los datosAhora cargamos los datos y los agregamos:
# cargamos los datos
data("puntuaciones")
puntuaciones <- puntuaciones |>
add_count(producto) |> # numero de observaciones de cada producto
mutate(producto_n = paste0(producto, " (n = ", n, ")")) |>
select(producto_n, puntuacion)
puntuaciones
#> # A tibble: 452 × 2
#> producto_n puntuacion
#> <chr> <dbl>
#> 1 Yogur (n = 8) 5
#> 2 Yogur (n = 8) 5
#> 3 Yogur (n = 8) 5
#> 4 Yogur (n = 8) 6
#> 5 Yogur (n = 8) 8
#> 6 Yogur (n = 8) 5
#> 7 Yogur (n = 8) 9
#> 8 Yogur (n = 8) 6
#> 9 Salsa de tomate (n = 8) 6
#> 10 Salsa de tomate (n = 8) 7
#> # ℹ 442 more rowsPor último, visualizamos los datos:
puntuaciones %>%
count(producto_n, puntuacion) |>
ggplot(aes(x = puntuacion, y = reorder(producto_n, puntuacion))) +
geom_vline(xintercept = 5, colour = "grey", size = 1) +
geom_point(aes(size = n), stroke = 0.5, colour = "orange") +
stat_summary(fun.data = "mean_se", geom = "pointrange",
size = 0.65, shape = 1, stroke = 1) +
labs(x = "Puntuaci\u00f3n",
y = "Producto",
colour = "Intervalo de confianza",
title = "Puntuaci\u00f3n asignada a cada producto",
subtitle = "Los c\u00EDrculos naranjas y barras de error indican la media y error t\u00EDpico") +
guides(size = guide_legend(nrow = 1)) +
scale_x_continuous(limits = c(-2.5, 10),
breaks = seq(-3, 10, 1)) +
theme_comidistar() +
theme(plot.title.position = "plot",
axis.title.y = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.major.x = element_line(colour = "grey", linetype = "dotted"),
legend.position = "top")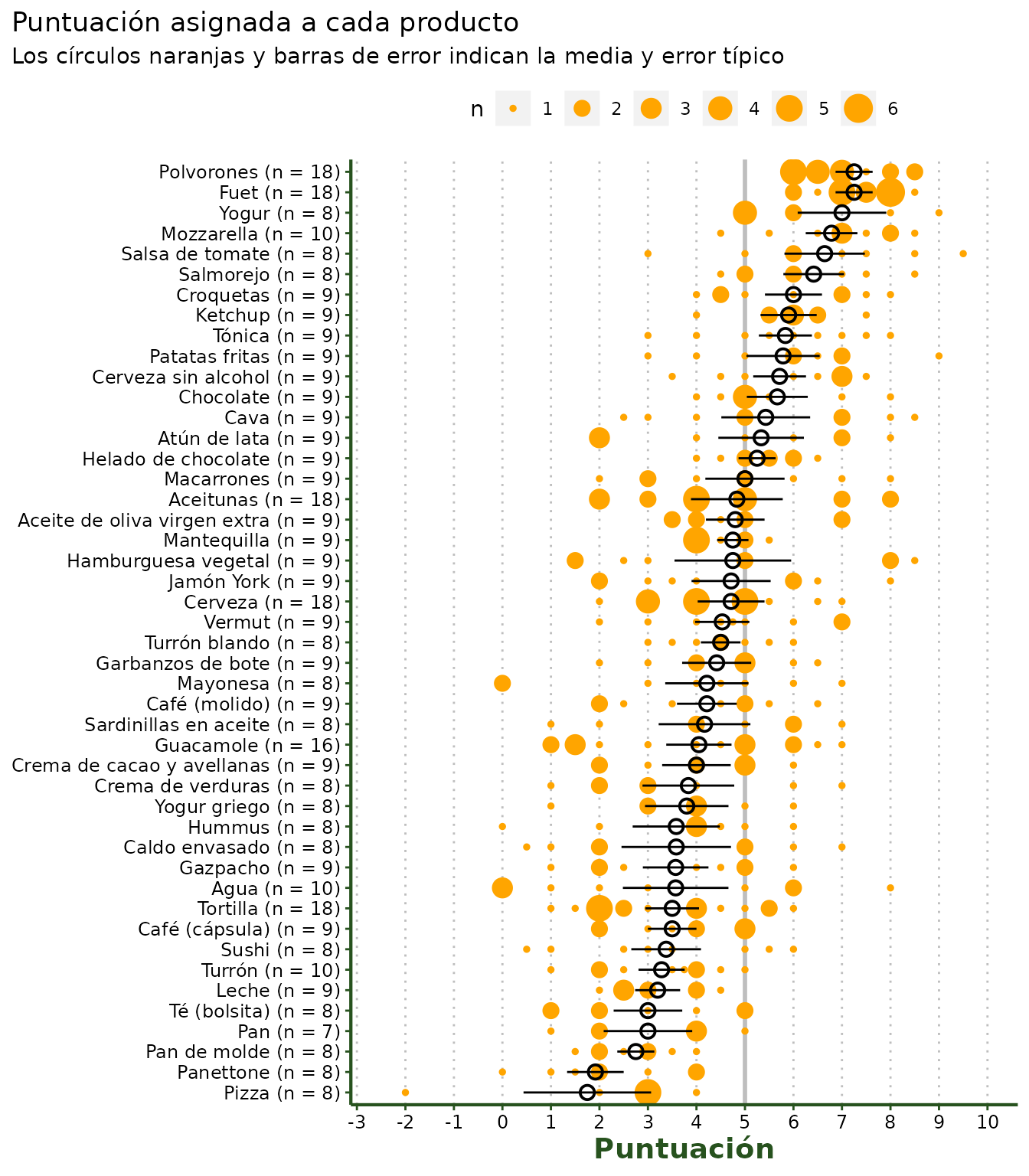
Distribución de las puntuaciones de las catas a ciegas para cada producto. Distribución de las puntuaciones (eje X) de cada producto (eje Y). El punto y su intervalo (en negro) indican la media y el intervalos que contiene el 95% de las puntuaciones de la distribución. Las líneas verticales dentro de cada distribuciu00f3n indican las puntuaciones individuales para cada marca, por parte de una de las personas del jurado.